
「Pythonを使えば、AIが魔法のようにデータを解析し、完璧なグラフを自動で生成してくれる」
かつての私は、そんなキラキラした期待を抱いていました。
しかし、5●歳になった現役の設計エンジニアとして、実務でPythonを使い倒している今なら断言できます。
設計DXの本質は、華やかな解析モデルの構築ではありません。その前段階にある、泥臭い「データの掃除(前処理)」にこそ、私たちの技術と魂を注ぐべきなのです。
かつて、あるVBAツールで100個以上の実験データをグラフ化した際、私は絶望的な経験をしました。
凡例の名前を一つ変えるだけの修正に、
「前のものは使えない。データを読み込み直して、最初から作り直してくれ」
と言い放たれたのです。
さらに、予告なく変更された線の太さや書体のせいで、過去のデータとの比較すら困難になっていました。
1箇所の寸法を直すために、図面を白紙から描き直せと言われるような理不尽さ。
「個人の気まぐれで、設計標準が書き換わる」。
そんな属人化の極致を目の当たりにした私は、二度とこんな不毛な作業を繰り返さないために、Pythonを手に取りました。
機械設計の世界では、不純物の混じった材料や、バリだらけの部品でいくら高度なCADを使っても、良い製品は生まれません。
データも同じです。
項目名がバラバラで、表記ゆれ(バリ)だらけのデータをそのまま放り込めば、解析結果という名の「不良品」が量産されるだけです。
この記事では、Javaで挫折し、VBAの属人化に振り回されてきた私が、なぜPythonのPandasを使って「データの掃除(前処理)」を最優先にしているのか。
そのマインドセットと、設計者がまず最初に行うべき「データの検収とバリ取り」の具体的な手法について解説します。
「退屈なことはPythonにやらせてみた」
そう決意したあの日から、私の設計業務がどう変わったのか。
そのリアルな一歩をお伝えします。
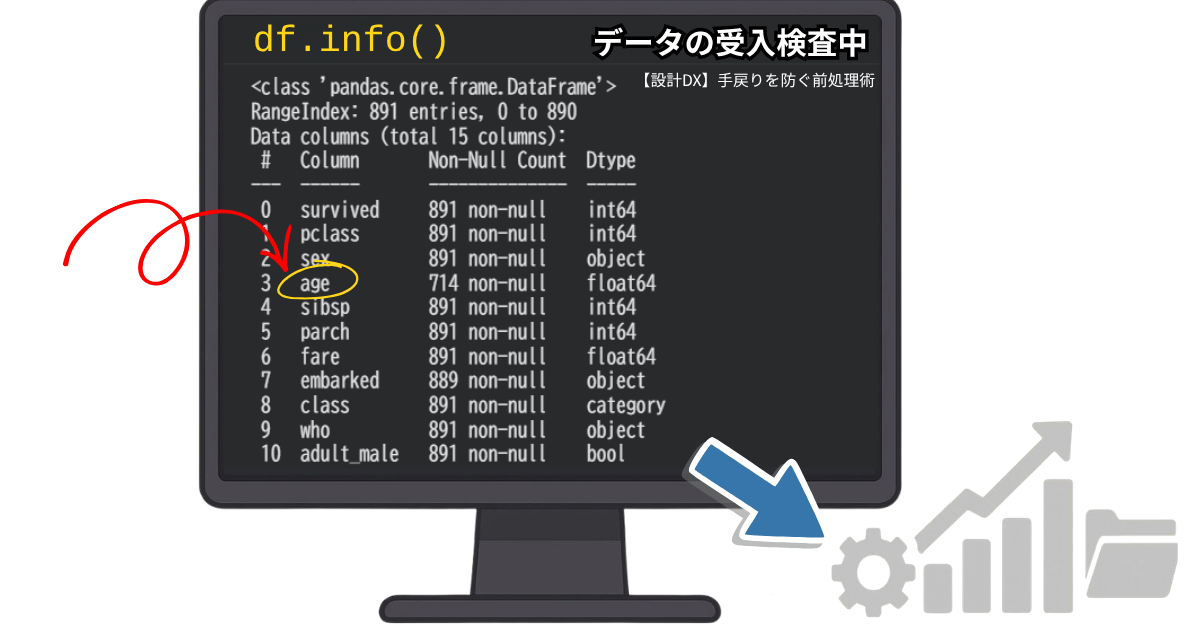
【検収】.info() は材料のデータの「受入検査」である
加工現場に材料が届いたとき、図面通りか、数量は合っているか、傷はないかを「受入検査」するように、Pythonでもデータが届いた瞬間にこのコマンドを叩きます。
Python
import pandas as pd
df = pd.read_csv('試験データ_20260510.csv')
print(df.info())この数行を実行した瞬間に、私たちはデータという名の材料に対して、以下の「検収作業」を一瞬で完了させることができます。
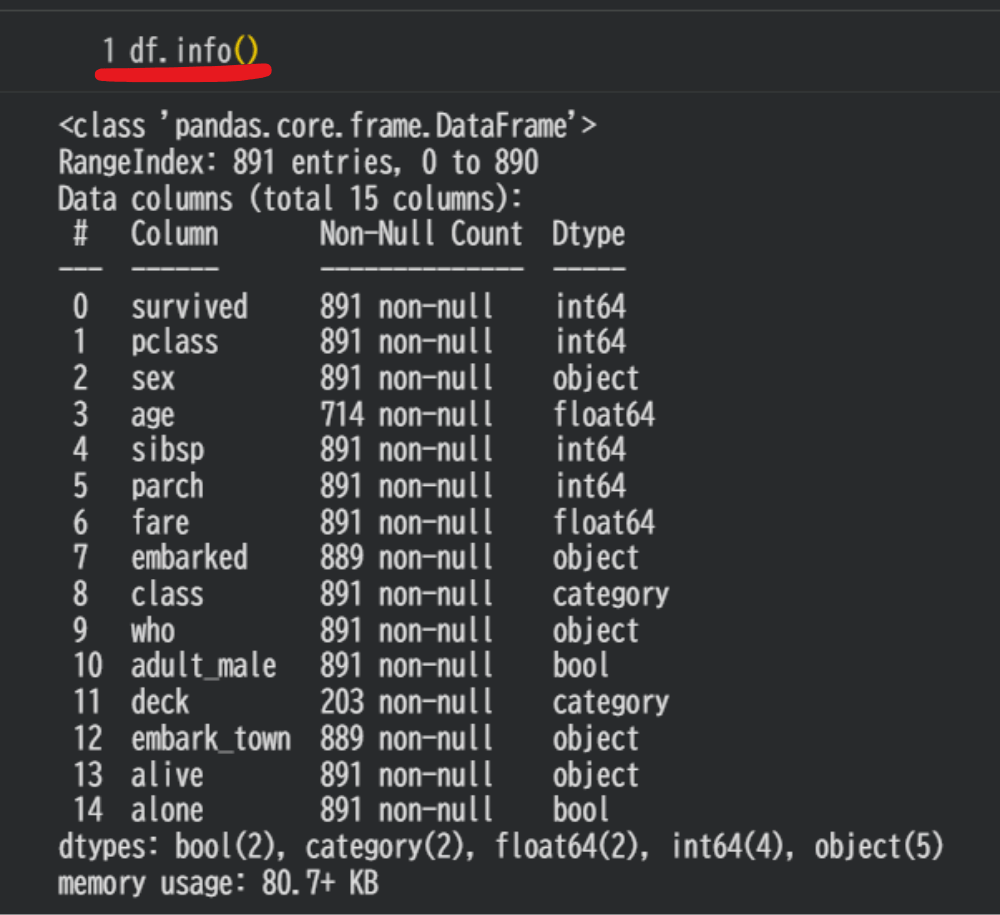
「ス(空洞)」の有無を確認する:Non-Null Count
図の「Non-Null Count」の列に注目してください。
例えば age の項目を見ると「714 non-null」となっています。
全891行に対して、データが欠落した「ス」が177箇所もあることが一目でわかります。
- 現場の感覚: 鋳物に空洞(ス)があれば強度が不足するように、欠損値があるデータで平均や最大値を出すと、解析結果という「製品」の信頼性が揺らぎます。
「100個あるはずの圧力が、95個しか記録されていない」といった異常を、グラフを描く前に発見できるのです。
「材質(型)」の適合性を確認する:Dtype
一番右の「Dtype」はデータの型、つまり「材質」です。
「圧力」や「時間」の列が float64(数値型) ではなく object(文字列型) になっていませんか?
- 現場の感覚: これは「アルミ材を削るつもりで超硬バイトをセットしたのに、届いた材料がゴムだった」ようなものです。
そのまま加工(計算)命令を出せば、エラーという名の「刃欠け」が起きます。
「構成点数」を把握する:RangeIndex / Columns
データの行数と列数を確認します。
- 現場の感覚: アセンブリのパーツリストと照らし合わせ、「予定通りの試験回数、予定通りの計測項目が揃っているか」の数量チェックです。
「アセンブリの規模」を把握する(Memory Usage)
下図のように、.info() はデータ全体のメモリ使用量も教えてくれます。
これは、CADでいうところの「ファイルサイズ」や「パーツ点数」の確認です。
あまりに巨大なデータであれば、扱い方を工夫しなければ動作が重くなるという予測が立ちます。
この数秒の「検収」が…。
この検収作業を怠ると
届いた材料をそのまま機械にかけ、途中で刃が折れたら「材料が悪い、最初からやり直せ」と言っているようなものです。
あの不便なVBAも、この基本的な受入検査をプログラムに組み込んでいなかったからこそ、現場に無理なやり直しを強いていたのでしょう。
私たちは、.info() という「デジタルマイクロメーター」を手に、まずは材料の素性を正しく見極めることから始めましょう。
この数秒の「検収」が、後工程での致命的な手戻りを防いでくれるのです。
【バリ取り】.unique() でデータの「表記ゆれ」を炙り出す
全体の受入検査(.info())が終わったら、次は各パーツの仕上がりを確認します。
ここで活躍するのが、データのバリエーションを重複なくリストアップする .unique() です。
設計現場で「図面番号は合っているが、現物の刻印が微妙に違う」「バリが残っていて組付けられない」という不具合を見つける作業に似ています。
「現物確認」の実行
例えば、試験対象の「型式」という項目にどんなデータが入っているか、現物を一つずつ並べて確認してみます。
Python
# 「型式」列のバリエーションを抽出
print(df["型式"].unique())実行結果に、以下のようなリストが表示されたとします。
['バルブA', 'バルブA', 'バルブA ', 'Valve_A']これがデータの「バリ」である
この結果を見た瞬間、設計者なら「おや?」と思うはずです。
- 半角と全角の混在:
バルブAとバルブA - 不要なスペース:
バルブA(末尾に空白がある) - 名称の不統一:
Valve_A
これらはすべて、同じ「バルブA」という部品を指しているはずですが、コンピュータはこれらを「全く別の4種類の部品」として認識してしまいます。
あのVBAツールで「凡例の名前がバラバラ」だったり、集計結果が合わなかったりした原因の多くは、この「バリ」を放置したままグラフ化に進んでしまったことにあります。
設計士の視点:まずは「数」で検収する
バリ(表記ゆれ)の中身を詳しく見る前に、まずは .nunique() で「種類数」をチェックしましょう。
Python
df["型式"].nunique()例えば、本来3種類しかないはずの型式が「4」と表示されたら、その時点で材料に不備があることが確定します。
現物(中身)を詳細に調べる前に、まずはこの数値で「異常」を察知するのが、手戻りを最小限にするコツです。
.unique() で「手戻り」を未然に防ぐ
本格的な計算やグラフ作成に入る前に、このコマンドで「バリエーション検査」を行う。
これだけで、後工程で「集計が合わない!」と青ざめるリスクを劇的に減らすことができます。
もし、種類が多すぎて数えきれない場合は、.nunique() を使えば「全部で何種類あるか」という個数だけを確認することも可能です。
見つけたバリ(表記ゆれ)は、削り取って形を整えなければなりません。
次は、このバラバラな名称を『正規の規格』へ一括で変換する、replace() によるバリ取り工程に進みましょう。
加工の前の「図面の持ち方」の確認
replace() でバリ取りを始める前に、設計者として絶対に押さえておきたい「お作法」があります。
それが、Pandasにおけるブラケット [] の数です。
- ブラケット1つ
df["型式"]:「パーツの単品図」 アセンブリから特定のパーツを抜き出し、その中身(材質や数値)に集中して計算や置換を行う状態です。
「強度計算」のように、数値そのものを加工したい時に使います。 - ブラケット2つ
df[["型式"]]:「アセンブリの構成管理」 1列だけであっても「表(アセンブリ)」という体裁を維持した状態です。
「構成表の編集」のように、他の項目と並べて管理したり、表としての枠組みを保ちたい時に使います。
「あのVBAで、なぜか1箇所直すと全体が壊れたのか。」
それは、パーツとアセンブリの区別がついていなかったからかもしれません。
Pythonでは、ブラケットの数ひとつで『今、何を対象にしているか』を明確に設計できるのです。
【規格化】replace() による「バリ取り」と「標準化」
受入検査(.info())で材料の素性を知り、現物確認(.unique())でバリを見つけたら、次はそのバリを削り取り、設計規格に適合させる「加工」に入ります。
ここで使うのが replace() という命令です。
これは、特定の不適切な名称を、正しい名称へと一括で書き換える「一斉置換ツール」です。
「修正指示書」を作成する
あのVBAのように、作成者の頭の中にしか修正ルールがない状態(属人化)を防ぐため、Pythonでは「辞書型」という形式で修正指示書(マッピング)を作成します。
Python
# { 'ダメな名前' : '正しい名前' } のリストを作る
mapping = {
'バルブA': 'バルブA',
'バルブA ': 'バルブA',
'Valve_A': 'バルブA'
}
# 指示書に従って、一括で「バリ取り」を実行
df["型式"] = df["型式"].replace(mapping)この数行を実行するだけで、数万行のデータに含まれる「表記ゆれ」が、一瞬で「バルブA」という正規の規格に統一されます。
なぜこれが「設計DX」なのか?
あの時、私が経験した「凡例の名前を直すために最初から作り直し」という悲劇。
それは、データとグラフの仕様が癒着していたことが原因でした。
Pythonでこの手順を踏むメリットは2つあります。
- 修正の「証跡」が残る: 「どの名前を、どう直したか」が
mappingというコード(指示書)として残ります。
これは図面における「改訂履歴」と同じです。
後から誰が見ても、なぜデータが書き換わったのかが明確になります。 - グラフへの連動(パラメトリック更新): 一度この「掃除の工程」を書いておけば、後で「やっぱり英語表記に統一して」と仕様変更が来ても、指示書を1行書き換えて再実行するだけです。
100個のグラフを読み込み直す必要はありません。
さらに言えば、この『修正指示書』を外部のExcelファイルにしておけば、Pythonがわからない現場の担当者でも修正ルールを更新できるようになります。
プログラム(治具)は変えず、設定(Excelの指示書)だけを変える。
これこそが、私が目指した属人化させない設計DXの形です。
材料を整え、加工の準備が整いました。
しかし、設計実務は1日では終わりません。
次は、今日頑張った『加工途中の仕掛品』を、明日の朝1秒で呼び出すための中間保存(Pickle)のテクニックを紹介します。
中間保存】Pickle(ピクルス)で「昨日の続き」を1秒で呼び出す
設計実務は、常に定時でキリ良く終わるわけではありません。
急な打ち合わせや電話で作業が中断されることも日常茶飯事です。
そんな時、せっかく .info() で受入検査をし、.unique() でバリを見つけ、replace() で綺麗に整えた「加工済みのデータ」を、どうやって保存していますか?
CSV保存は「図面をシュレッダーにかける」ようなもの
多くの人がやってしまいがちなのが、作業途中のデータを一度CSVで書き出すことです。
しかし、これはお勧めしません。
- 理由: CSVはただの「テキスト(文字)」の集まりです。
せっかく数値型(float)に整えた設定や、特殊な並び順(インデックス)といった「データの素性」が全て消えてしまいます。 - 次の日、そのCSVを読み込むと、また最初から「受入検査」をやり直すハメになります。
これは、せっかく組んだアセンブリをバラバラにして、部品を袋に詰めて帰るようなものです。
Pickle(ピクルス)は「3Dアセンブリの中間保存」
そこで使うのが Pickle(ピクルス) 形式での保存です。
名前の通り、データを「塩漬け(凍結保存)」にする機能です。
- 保存する時(昨日の終わり):Python
df.to_pickle('中間データ_加工済み.pkl') - 読み込む時(今日の始まり):Python
df = pd.read_pickle('中間データ_加工済み.pkl')
「型」も「構造」も、そのままフリーズ
Pickleで保存すると、Pandasが管理している「型(材質)」や「見出し(構成)」の情報がそのまま丸ごと保存されます。
- 現場の感覚: 次の日の朝、ファイルを開いた瞬間に、昨日の作業終了時の「3Dアセンブリ画面」がそのまま立ち上がるような感覚です。
材料を整える「前準備」に時間をかけるからこそ、その成果を100%維持したまま次工程(グラフ化や解析)へ渡す。
この中間保存のルール化が、手戻りを防ぎ、属人化させない「設計DX」の最後のピースになります。
たかが前準備(データの掃除)に、なぜここまで時間をかけるのか?
「たかが前準備(データの掃除)に、なぜここまで時間をかけるのか?」
かつての私なら、そう思っていたかもしれません。
しかし、100個のグラフを「見た目が違うから」という理由だけで白紙から描き直したあの日、私は痛感しました。出口(グラフ)だけを自動化しても、そこに至る「工程」と「材料(データ)」が標準化されていなければ、それは真の自動化ではないということを。
今回ご紹介した4つのステップは、地味で泥臭い作業に見えるかもしれません。
.info()による受入検査:材料の「ス」や「材質違い」を見逃さない。.unique()によるバリ取り:表記ゆれという名の「不具合品」を炙り出す。replace()による規格化:修正指示書(辞書型)に基づき、属人化を排除して加工する。Pickleによる中間保存:加工済みの「仕掛品」を翌日に1秒で呼び出す。
これらを徹底することで、私の設計実務は劇的に変わりました。
仕様変更がきても、もう怒る必要はありません。
修正指示書を一行書き換え、再実行ボタンを押すだけ。
5分後には、完璧に規格化された100個のグラフが目の前に並びます。
「退屈なことはPythonにやらせてみた」。
その結果、私が手に入れたのは「自由な時間」だけではありません。
どんなデータの乱れにも動じない、設計者としての「仕事の品質への自信」です。
もし、あなたがかつての私と同じように、データの表記ゆれや理不尽なやり直しに疲弊しているのなら、まずはこの「掃除」から始めてみてください。
その一歩が、あなたの設計者としての価値を、さらに高めてくれるはずです。

